16. Методы статистического анализа результатов выборов (корреляции, Гаусс, Бенфорд и все-все-все)
Результатом анализа множества исследований, опубликованных в СМИ и блогах по результатам предыдущих выборов, является вывод о том, что хоть и не все, но большинство популярных мнений о статистических свидетельствах фальсификаций являются либо грубыми математическими и логическими ошибками, либо чьими-то спланированными манипуляцими.
Цель данной статьи — в преддверии президентских выборов ЗАРАНЕЕ подготовить весь возможный арсенал статистических исследований будущих результатов. С тем, чтобы не допустить ошибок и манипуляций, а последовательно применить уже проверенные математические методы.
Взамен ошибочных и неточных предлагается несколько других, гораздо более корректных и научно обоснованных методов оценки достоверности результатов выборов.
Цель данной статьи — в преддверии президентских выборов ЗАРАНЕЕ подготовить весь возможный арсенал статистических исследований будущих результатов. С тем, чтобы не допустить ошибок и манипуляций, а последовательно применить уже проверенные математические методы.
Взамен ошибочных и неточных предлагается несколько других, гораздо более корректных и научно обоснованных методов оценки достоверности результатов выборов.
Философия
 Обнаружение удивительных на первый взгляд явлений вовсе не означает присутствия «разумного замысла». Те, кто сразу начинает кричать о подтасовках и фальсификациях, обнаружив любой необычный статистический график, напоминают древних мудрецов, которые, увидев яркую молнию, заявляли, что это Зевс-громовержец гневается, не иначе. Однако на протяжении последних веков наука шаг за шагом уверенно демонстрирует нам, что многие удивительнейшие явления имеют абсолютно естественную природу.
Обнаружение удивительных на первый взгляд явлений вовсе не означает присутствия «разумного замысла». Те, кто сразу начинает кричать о подтасовках и фальсификациях, обнаружив любой необычный статистический график, напоминают древних мудрецов, которые, увидев яркую молнию, заявляли, что это Зевс-громовержец гневается, не иначе. Однако на протяжении последних веков наука шаг за шагом уверенно демонстрирует нам, что многие удивительнейшие явления имеют абсолютно естественную природу.
Многочисленныеблоггеры шаманы манипулируют сознанием людей, показывая красивые графики и распределения, восклицая при этом о несомненном воздействии богов Кремля Олимпа, приведшем к столь чудесным картинкам. При этом сии борцы за справедливость часто допускают грубейшие логические и математические ошибки, пользуясь тем, что в толпе их последователей (и журналистов) мало кто разбирается в этой науке, далеко выходящей за рамки школьной программы. Эти ошибки не только ставят под сомнение общие выводы, но и сильно дискредитируют само (совершенно правильное по сути!) движение «за честные и справедливые выборы».
Поэтому давайте внимательно и заранее, ещё до объявления результатов президентских выборов 2012, разберёмся, какие статистические эффекты в результатах голосований действительно являются свидетельством «вмешательства сверху», а какие объяснимы без привлечения потусторонней силы.
Основные подозреваемые
Два самых популярных объекта поиска аномалий:
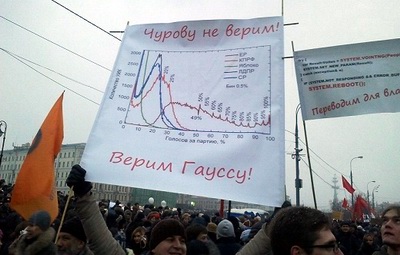
«График А» — распределение числа участков в зависимости от процента голосов за партию (либо от процента явки).


«График Б» — корреляция между явкой на избирательных участках и процентом голосов за партии.


Итак, давайте перечислим все возможные статистические методы исследований результатов выборов. Начнём с популярных заблуждений:
Категория 1. «Светлая зона — привидений точно нет.»
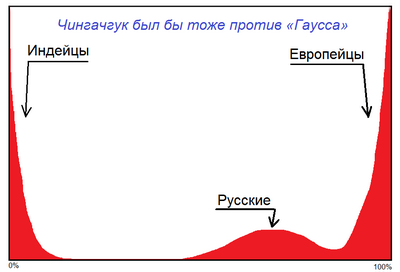 1.1) График А обязан иметь ровную симметричную форму «колокола» (распределение Гаусса, оно же нормальное распределение).
1.1) График А обязан иметь ровную симметричную форму «колокола» (распределение Гаусса, оно же нормальное распределение).
Шаманы говорят: «Cмотри, народ, в любых случайных процессах наблюдается Гаусс! Хочешь пульки в мишень стреляй, хочешь одноклассников по росту измеряй — везде Гаусс! Одно только распределение голосов за Единую Россию, да явка на выборы в ГосДуму — горбатые монстры с диавольским хвостом!»
Но дело в том, что люди — не пульки, и голосуют они не случайным образом, и голоса их по избирательным участкам распределены ну никак не независимо.
Представьте себе, что в 1760 году в Северной Америке устраивают президентские выборы. Две кандидатуры — Чингачгук Большой Змей и Георг II. Кто-то усомнится в том, что График А для таких голосований будет, мягко говоря, не похож на гаусса? УИК'и, находящиеся в вигвамах, очевидно, покажут 100% за первого кандидата и 0% за второго, а УИК'и в городских мэриях — строго наоборот.
Если бы людей приписывали к случайно выбранным участкам — тогда да, был бы чёткий гаусс. Но раз участки выбираются не случайно, а по территориальному признаку, то распределение обязано зависеть от географических неоднородностей предпочтений электората. В заводском посёлке одно распределение, в воинской части — другое, в фешенебельном центре города — третье. В северной области — одно, в южной республике — другое. В разных местах люди живут по-разному, и поэтому по-разному относятся к правящей партии. Причём особые отклонения от гаусса будут именно для правящей партии, т.к. о ней люди судят по реальным делам, и дела эти везде, к сожалению, разные. А о не-правящих партиях люди судят, в основном, по информации из СМИ, а та в наш век вполне однородна — и бабуля в деревне, и мажор в пентхаусе смотрят, в принципе, один и тот же телевизор.
 В официальных пояснениях к графикам распределений голосов в результатах президентских выборов 2008 на сайте ЦИК показано, что за негауссовость того конкретного графика отвечало в основном разделение участков на городские-сельские-другие. (Но это не означает, что стоит только разделить график на город/село, как он тут же распадётся на два гаусса. Это лишь одна из многих, далеко не единственная причина возникновения негауссовых распределений.)
В официальных пояснениях к графикам распределений голосов в результатах президентских выборов 2008 на сайте ЦИК показано, что за негауссовость того конкретного графика отвечало в основном разделение участков на городские-сельские-другие. (Но это не означает, что стоит только разделить график на город/село, как он тут же распадётся на два гаусса. Это лишь одна из многих, далеко не единственная причина возникновения негауссовых распределений.)
При этом, чем больше неоднородность страны, тем больше шансов, что итоговая кривая будет иметь «неправильную» форму. А в условиях кризиса, который по-разному сказался на различных группах населения, рост поляризации мнений ещё более вероятен. Отсюда большая, по сравнению с некоторыми предыдущими выборами, неоднородность графика.
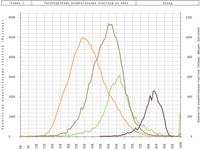
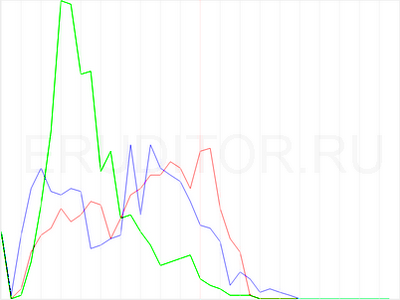
Совсем упорным последователям религии Всемогущего Гаусса могу предложить взглянуть на аналогичные графики результатов голосований в других странах. В первую очередь тех, демократичность которых у нас особых сомнений не вызывает. График для парламентских выборов в Великобритании (2010) я строил сам лично, он приведён справа →
На нём видно, что только для одной партии (зелёная линия) график хоть как-то похож на гаусса, но и то с довольно толстым хвостом справа. У двух остальных партий — совсем не гауссовые многогорбые чудища.
Ссылки на исследования выборов в разных странах:
— Германия: http://jemmybutton.livejournal.com/1638.html
— США: http://reverent.org/ru/negaussovi_vibori_usa/
— Польша: http://aftershock-su.livejournal.com/4347.html
— Израиль: http://levrrr.livejournal.com/31427.html
— Великобритания: http://mi-b.livejournal.com/218931.html
Все эти исследования показывают, что в порыве страстного желания обвинить власть во всех возможных грехах, наши борцы за справедливость, мягко говоря, переборщили — множество статистических «аномалий», которые послужили основанием для самых грязных обвинений и радикальных лозунгов, в действительности совершенно корректны.
1.2) На графике А острый пик ровно на 50% свидетельствует о подтасовке с целью перевалить за заветное число в 50%.
Это хоть и нетривиальный, но объяснимый математический эффект. Связан он с тем, что процент голосов — не простая случайная величина, а частное от деления двух ЦЕЛЫХ чисел — количества голосов за партию и общего числа избирателей. А среди всевозможных дробей N/M число 1/2 встречается гораздо чаще остальных. Поэтому на ЛЮБОМ распределении процентов голосов будет очень узкий, но, при достаточно мелком шаге гистограммы, всё же видимый пик строго на 50%.
При выборе достаточно мелкого шага гистограммы будут появляться (и сильно возмущать) острые пики и на других круглых числах: 1/4=25%, 2/5=40%, 3/5=60%, 2/3≈65%, 3/4=75%, 4/5=80% и т.д. При выявлении аномалий на круглых числах следует обязательно учитывать данный эффект. Подробнее см. в этой статье и во многих других. (О других особенностях «пиков на круглых процентах» см. дальше.)
 1.3) Срезанные верхушки на графиках распределений проигравших партий свидетельствуют о том, что часть их голосов была переписана на счёт победившей партии.
1.3) Срезанные верхушки на графиках распределений проигравших партий свидетельствуют о том, что часть их голосов была переписана на счёт победившей партии.
Как было отмечено выше в п.1.1), распределение голосов для правящей партии принципиально отличается от распределения для новой, «синтетической» партии, которую народ знает только по глобальной информации из СМИ. Однако помимо правящей партии есть ещё и правИВшие. Для них также следует ожидать заметных отклонений от гаусса.
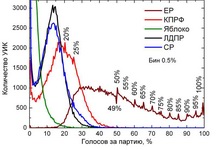
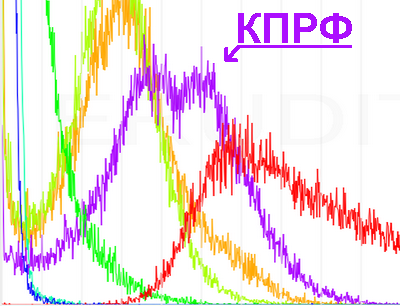
Например, на графике А для выборов в ГосДуму-2011 ясно видно, что электорат Коммунистической партии состоит из двух близких, но, тем не менее, отличающихся групп. Не исключено (это лишь гипотеза), что эти два близких гауссовых горба представляют из себя две группы электората — тех, кто жил при КПСС, и тех, кто ту эпоху уже не застал. Территориальную зависимость в голосовании за КПРФ можно попробовать проследить по фактору город/деревня, либо даже в пределах одного города по возрасту домов, которые относятся к данным УИК (в новостройках больше процент молодёжи, а в старых домах больше пожилых людей).
1.4) Задирание вверх графика распределения голосов на 100% для правящей партии и в 0% для остальных свидетельствует о фальсификации.
Не свидетельствует. Это естественный граничный эффект — в примере с Чингачгуком распределение размазано по вертикальным стенкам в 0% и 100% без всяких махинаций.
Как так получается, что у победившей партии нет пика в 0%, как у остальных, и наоборот, ни у кого, кроме победителя, нет пика на 100%? Любое распределение, которое левым краем упирается в 0%, будет иметь там острый пик, а любое распределение, достающее до 100% — там. Когда есть явный лидер в голосовании, никто кроме него до 100% не дотягивает, а сам победитель далёк от 0%.
1.5) На графике Б корреляция между явкой на избирательных участках и процентом голосов за правящую партию свидетельствует о вбросе бюллетеней с «нужными» голосами.
Для начала, очень важное соображение, которое упускают многие исследователи:
Наличие корреляции между величинами А и Б вовсе не означает наличия прямой причинно-следственной связи между ними.
Например, рассмотрим два параметра, характеризующих пожары в определённом городе:
А — нанесённый пожаром ущерб
Б — количество пожарных, участвовавших в ликвидации этого пожара
Между величинами А и Б существует высокая положительная корреляция — как правило, чем больший был нанесён ущерб, тем одновременно и больше пожарных участвовало в тушении. Но будет полным абсурдом утверждать, что ПРИЧИНОЙ большого ущерба стало большое количество пожарных. (См. статью «Корреляция» в Википедии.)
Результаты выборов в Парламент Великобритании 2010 показывают ещё более сильную зависимость между явкой и процентом голосов за разные партии:
(Подробнее см. в предыдущей статье.)
У этой зависимости может быть множество совершенно естественных причин. Почему конкретно так обстоят дела для Консервативной и Лейбористской партий в Великобритании я не знаю, но вот про корреляцию для российских реалий есть вполне чёткая логика.
В сознании законопослушных постсоветских граждан тесно связаны действия «прийти на выборы» и «проголосовать за действующую власть». Долгие годы однопартийной системы приучили людей к тому, что «сходить проголосовать» и «сходить проголосовать за власть» — синонимы. А правящая партия стойко ассоциируется с властью-вообще. Обычно за оппозиционную партию голосуют только те, кто твёрдо уверен в необходимости голосовать именно за неё. А за правящую партию голосуют в том числе и те, кто просто считает нужным «проголосовать», хотя и не особо-то разбирается в политике — просто так положено.
Вообще, игра на корреляции явки и процента голосов — вовсе не новость. Помните «Голосуй или проиграешь» в 1996-м? Штаб Ельцина выбрал очень грамотную линию — тащить на выборы молодёжь, которая одновременно а) за Ельцина (потому что против коммунистов) и б) крайне пассивна в плане «сходить на выборы». Аналогичную стратегию увеличения одновременно и голосов за себя, и общей явки использовал Билл Клинтон («Choose or lose»).
1.6) На графике Б наличие у правящей партии положительной корреляции, а у оппозиции — отрицательной свидетельствует о том, что часть голосов забрали у оппозиции и переписали их «куда надо».
Это совсем глупая ошибка, сильно дискредитирующая статьи Сергея Шпилькина и его последователей. Рассматривать явно ЗАВИСИМЫЕ величины и удивляться, что они взаимно коррелируют — вот уж действительно «чудо». Ведь число «явка» — это сумма количеств голосов за партии: A=K1+K2+...+Kn. Из (n+1) чисел {A,K1,K2,...,Kn} лишь (n) чисел могут быть независимы. Поэтому появления по какой-либо причине корреляции между голосованием за ОДНУ ЛЮБУЮ партию достаточно для появления корреляции и для всех остальных партий.
Допустим, на выборах в Америке-1760 появился третий кандидат — Оцеола, вождь семинолов, который призвал верных ему людей бойкотировать выборы. В результате на тех участках, где живут семинолы (и где естественный высокий процент голосов за Оцеолу) будет низкая явка — появится отрицательная корреляция: чем выше на участке явка, тем меньше там голосов за Оцеолу. Но, мало того, это автоматически приведёт и к появлению компенсирующей её положительной корреляции — чем выше на участве явка, тем больше там процент голосов за Чингачгука, хотя Чингачгук никоим образом к этому эффекту не причастен.
Ещё более грубая ошибка в расчётах корреляции заведомо зависимых величин (для случая, когда процент голосов высчитывается от списочного состава, как это делалось в оригинальных статьях Шпилькина) подробно разобрана здесь: http://xp-cmdshell.livejournal.com/273519.html
Категория 2. «Сумеречная зона — то ли есть, то ли нет, но что-то нехорошее точно мерещится.»
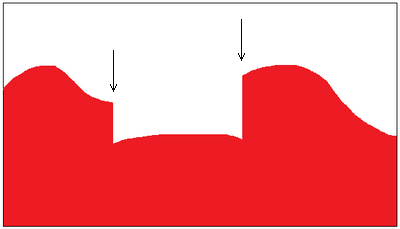 2.1) Вертикальные вырезы на графике А.
2.1) Вертикальные вырезы на графике А.
Выше мы подробно обсудили, что реальное распределение вовсе не обязано быть гауссом из-за чисто географической неоднородности отношения к кандидату. Однако центральную предельную теорему всё-таки никто не отменял, и на участках, где всё более-менее однородно, должен быть гаусс (но только на отдельных участках!).
Таким образом, итоговый результат сложения всех этих участков будет суммой нескольких гауссовых «колоколов» — этакой многогорбой кривой. Однако, гауссы — ровные, и в середине распределения обычно довольно широкие. Поэтому получить путём их сложения отвесную вертикальную стенку естественным образом крайне сложно.
К сожалению, даже при таких объёмах данных, какие есть на всероссийских выборах, статистические выбросы слишком портят картинку, чтобы можно было с уверенностью утверждать наличие такой аномалии. На графике Единой России на выборах в ГосДуму 2011 есть подозрительные участки с почти вертикальными стенками на 36%, 65%, 70%, 79%, 90%. (Подробнее см. дальше, в Зоне тьмы.)
2.2) КОИБы и КЭГи
Наличие существенно различных картин данных с участков, где установлены комплексы обработки избирательных бюллетеней (КОИБ) и участков, где учёт бюллетеней ведётся вручную, ПРИ УСЛОВИИ, что КОИБы расставлены достаточно равномерно, также не может не вызывать подозрений. Однако ещё раз отметим — для того, чтобы данный фактор имел хоть какое-то значение, обязательно необходимо, чтобы статистика КОИБов была достаточно репрезентативной. Если КОИБы устанавливать только в салунах, не имея ни одного из них в вигвамах, то удивляться разнице в результатах голосования не приходится. А на данный момент расстановка КОИБов далека от равномерной (возможно, к президентским выборам ситуация изменится, да и веб-камеры обещают повесить).
Также при анализе корреляции следует учитывать «третий фактор» — из корреляции А и Б не следует то, что А является причиной Б, т.к. вполне возможно, что существует какой-то фактор В, из которого следуют оба — и А, и Б (помните аналогию про пожарников?). Например, низкий процент голосов за ЕР на автоматизированных участках в Коми может быть следствием вовсе не автоматизированности участков, а того, что, по словам самого исследователя, «на автоматизированные УИКи нагоняли людей с открепительными».
Наличие таких корреляций никогда не может быть строгим доказательством намеренной подтасовки, т.к. всегда остаётся шанс, что этот самый «третий фактор» существует, но просто не был найден.
Категория 3. «Зона кромешной тьмы.»
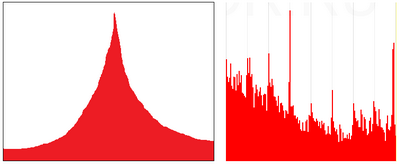 3.1) Многочисленные острые вогнутые пики на графике А.
3.1) Многочисленные острые вогнутые пики на графике А.
В п.2.1) мы пришли к тому, что хоть итоговый график распределения и не обязан быть гауссом сам по себе, он, скорее всего, должен состоять из нескольких (возможно, многих) гауссов. Эти рассуждения приводят нас к выводу о ненатуральности острых, направленных вверх пиков с вогнутыми вниз склонами (гауссы вблизи вершины выгнуты вверх!).
На данный момент автору не известны какие-либо разумные объяснения подобных аномалий, особенно когда они возникают на круглых значениях процентов, как это есть на уже упоминавшемся графике «ЕР: ГД 2011», его фрагмент приведён справа →
Это единственное достоверное статистическое подтверждение наличия фальсификаций на выборах в ГосДуму РФ 2011. Детальный анализ показывает, что за появление «шипованого хвоста» ответственны наши горячие и чересчур лояльные властям южные республики, что, в общем, совсем не удивительно.
3.2) Явные нарушения закона Бенфорда.
И, на десерт, исследование, которому уделяется незаслуженно мало внимания.
Дело в том, что «рукописные», сочинённые человеком числа с точки зрения самих ЦИФР, которыми записываются эти числа, отличаются от естественных. Причём эти закономерности противоречат нашему «бытовому» здравому смыслу, поэтому вручную их ОЧЕНЬ сложно сымитировать при фальсификации.
Цифр, как известно, 10. Из них первой цифрой числа может быть только 9 (все, кроме нуля). Поэтому, казалось бы, вероятность появления единицы среди первых цифр в колонке чисел должна быть 1/9=11%. Но на самом деле для огромного множества естественных наборов чисел вероятность того, что первой цифрой окажется единица, гораздо больше — 30%! Этот удивительный факт установил в 1938 году физик Фрэнк Бенфорд. И с тех пор он успел уже не только помочь в выявлении подлогов бухгалтерских отчётов, но и, что нас куда больше интересует, обосновал подозрения в фальсификации выборов в Иране (2009) (in english, по-русски).
В Википедии есть подробная статья про закон Бенфорда для случая первой цифры, но в полной форме он описывает встречаемость цифр на любой позиции. Чем ближе цифра к началу числа, тем ближе распределение вероятностей к бенфордовскому, а чем дальше — к равномерному.
Итак, вероятность появления данной цифры в качестве первой цифры числа логарифмически падает: единицу мы встретим в 30% случаев, а восьмёрку и девятку лишь в 5% (в шесть раз реже, чем единицу!).
Последние же цифры длинных чисел распределены равномерно — вероятность встретить в конце (длинного!) числа любую цифру обязана быть равна 10%.
Проверка закона Бенфорда для результатов выборов в ГосДуму 2011 (XLS).
Видно, что:
а) Закон Бенфорда для чисел голосов за партии (Единой России в том числе) выполняется просто фантастически красиво и для первой цифры, и для второй (см. xls), и для последней. Статистика выборов в ГосДуму 2011 — вообще уникальный массив данных для иллюстрации закона Бенфорда ;-)
б) Зелёная полоска на цифре «2» — объяснимый выброс. Списочное количество избирателей — не случайное число, на него действуют установленные ЦИК правила об оптимальном размере избирательного участка (видимо, порядка 1500-2500). Поэтому очень много участков, где 2*** избирателей, но резко меньше, где 3***.
Особенность закона Бенфорда в том, что он не работает, если есть хоть какая-то причина ему не работать (когда в системе существует заданный снаружи порядок вещей). Но когда таких причин нет — ему следует доверять.
в) На графике для первых цифр подозрительная «сумеречная» аномалия, касающаяся явки (розовая полоска). В хвосте распределения (цифры 5,6,7,8,9), где все партии логарифмически падают вместе с бенфордом, колонка явки не только не падает вместе со всеми, но и даже растёт!
Данная аномалия согласуется с фактом некоторого числа поддельных результатов, но почему-то только относительно приписок явки на выборы, а не вброса для какой-то конкретной партии. Вероятно, за этим кроется какая-то более хитрая логика.
Категория 4. Фильсификации фальсификаций.
4.1. ruelect.com
Подивившись точности закона Бенфорда, я решил проверить его на ещё каком-нибудь наборе чисел. Под руку подвернулся сайт ruelect.com, на котором народ собирает «настоящие» протоколы голосований, дабы продемонстрировать, что они никак не стыкуются с данными ЦИК (ЕдРо, дескать, ворует голоса). Честно говоря, после таких новостей доверие к ruelect.com и без того пошатнулось, но результат всё равно меня поразил. Итак:
Степень соответствия закону Бенфорда количества голосов за ЕР: слева — по данным ЦИК, справа — по данным ruelect.com:
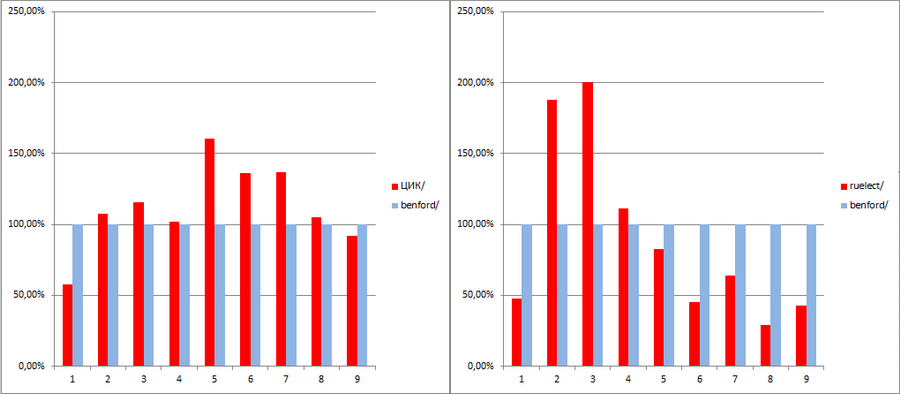
(На диаграмме показано отношение количества указанных первых цифр к прогнозируемому значению, следующему из закона Бенфорда.)
(В выборке, в т.ч. данных ЦИК, участвуют только те участки, которые приведены в базе ruelect.com.)
Видно, что якобы достоверные данные ruelect.com ГОРАЗДО ХУЖЕ следуют закону Бенфорда, чем якобы фальсифицированные данные ЦИК. Дабы не уподобляться «шаманам», поспешных выводов из этого факта я делать не буду, но подозрения он вызывает более чем серьёзные.
Обсуждение (ЖЖ).
Обнаружение удивительных на первый взгляд явлений вовсе не означает присутствия «разумного замысла». Те, кто сразу начинает кричать о подтасовках и фальсификациях, обнаружив любой необычный статистический график, напоминают древних мудрецов, которые, увидев яркую молнию, заявляли, что это Зевс-громовержец гневается, не иначе. Однако на протяжении последних веков наука шаг за шагом уверенно демонстрирует нам, что многие удивительнейшие явления имеют абсолютно естественную природу.Многочисленные
Поэтому давайте внимательно и заранее, ещё до объявления результатов президентских выборов 2012, разберёмся, какие статистические эффекты в результатах голосований действительно являются свидетельством «вмешательства сверху», а какие объяснимы без привлечения потусторонней силы.
Основные подозреваемые
Два самых популярных объекта поиска аномалий:
«График А» — распределение числа участков в зависимости от процента голосов за партию (либо от процента явки).
«График Б» — корреляция между явкой на избирательных участках и процентом голосов за партии.
Итак, давайте перечислим все возможные статистические методы исследований результатов выборов. Начнём с популярных заблуждений:
Категория 1. «Светлая зона — привидений точно нет.»
1.1) График А обязан иметь ровную симметричную форму «колокола» (распределение Гаусса, оно же нормальное распределение). Шаманы говорят: «Cмотри, народ, в любых случайных процессах наблюдается Гаусс! Хочешь пульки в мишень стреляй, хочешь одноклассников по росту измеряй — везде Гаусс! Одно только распределение голосов за Единую Россию, да явка на выборы в ГосДуму — горбатые монстры с диавольским хвостом!»
Но дело в том, что люди — не пульки, и голосуют они не случайным образом, и голоса их по избирательным участкам распределены ну никак не независимо.
Представьте себе, что в 1760 году в Северной Америке устраивают президентские выборы. Две кандидатуры — Чингачгук Большой Змей и Георг II. Кто-то усомнится в том, что График А для таких голосований будет, мягко говоря, не похож на гаусса? УИК'и, находящиеся в вигвамах, очевидно, покажут 100% за первого кандидата и 0% за второго, а УИК'и в городских мэриях — строго наоборот.
Если бы людей приписывали к случайно выбранным участкам — тогда да, был бы чёткий гаусс. Но раз участки выбираются не случайно, а по территориальному признаку, то распределение обязано зависеть от географических неоднородностей предпочтений электората. В заводском посёлке одно распределение, в воинской части — другое, в фешенебельном центре города — третье. В северной области — одно, в южной республике — другое. В разных местах люди живут по-разному, и поэтому по-разному относятся к правящей партии. Причём особые отклонения от гаусса будут именно для правящей партии, т.к. о ней люди судят по реальным делам, и дела эти везде, к сожалению, разные. А о не-правящих партиях люди судят, в основном, по информации из СМИ, а та в наш век вполне однородна — и бабуля в деревне, и мажор в пентхаусе смотрят, в принципе, один и тот же телевизор.
В официальных пояснениях к графикам распределений голосов в результатах президентских выборов 2008 на сайте ЦИК показано, что за негауссовость того конкретного графика отвечало в основном разделение участков на городские-сельские-другие. (Но это не означает, что стоит только разделить график на город/село, как он тут же распадётся на два гаусса. Это лишь одна из многих, далеко не единственная причина возникновения негауссовых распределений.)При этом, чем больше неоднородность страны, тем больше шансов, что итоговая кривая будет иметь «неправильную» форму. А в условиях кризиса, который по-разному сказался на различных группах населения, рост поляризации мнений ещё более вероятен. Отсюда большая, по сравнению с некоторыми предыдущими выборами, неоднородность графика.
Совсем упорным последователям религии Всемогущего Гаусса могу предложить взглянуть на аналогичные графики результатов голосований в других странах. В первую очередь тех, демократичность которых у нас особых сомнений не вызывает. График для парламентских выборов в Великобритании (2010) я строил сам лично, он приведён справа →
На нём видно, что только для одной партии (зелёная линия) график хоть как-то похож на гаусса, но и то с довольно толстым хвостом справа. У двух остальных партий — совсем не гауссовые многогорбые чудища.
Ссылки на исследования выборов в разных странах:
— Германия: http://jemmybutton.livejournal.com/1638.html
— США: http://reverent.org/ru/negaussovi_vibori_usa/
— Польша: http://aftershock-su.livejournal.com/4347.html
— Израиль: http://levrrr.livejournal.com/31427.html
— Великобритания: http://mi-b.livejournal.com/218931.html
Все эти исследования показывают, что в порыве страстного желания обвинить власть во всех возможных грехах, наши борцы за справедливость, мягко говоря, переборщили — множество статистических «аномалий», которые послужили основанием для самых грязных обвинений и радикальных лозунгов, в действительности совершенно корректны.
1.2) На графике А острый пик ровно на 50% свидетельствует о подтасовке с целью перевалить за заветное число в 50%.
Это хоть и нетривиальный, но объяснимый математический эффект. Связан он с тем, что процент голосов — не простая случайная величина, а частное от деления двух ЦЕЛЫХ чисел — количества голосов за партию и общего числа избирателей. А среди всевозможных дробей N/M число 1/2 встречается гораздо чаще остальных. Поэтому на ЛЮБОМ распределении процентов голосов будет очень узкий, но, при достаточно мелком шаге гистограммы, всё же видимый пик строго на 50%.
При выборе достаточно мелкого шага гистограммы будут появляться (и сильно возмущать) острые пики и на других круглых числах: 1/4=25%, 2/5=40%, 3/5=60%, 2/3≈65%, 3/4=75%, 4/5=80% и т.д. При выявлении аномалий на круглых числах следует обязательно учитывать данный эффект. Подробнее см. в этой статье и во многих других. (О других особенностях «пиков на круглых процентах» см. дальше.)
1.3) Срезанные верхушки на графиках распределений проигравших партий свидетельствуют о том, что часть их голосов была переписана на счёт победившей партии. Как было отмечено выше в п.1.1), распределение голосов для правящей партии принципиально отличается от распределения для новой, «синтетической» партии, которую народ знает только по глобальной информации из СМИ. Однако помимо правящей партии есть ещё и правИВшие. Для них также следует ожидать заметных отклонений от гаусса.
Например, на графике А для выборов в ГосДуму-2011 ясно видно, что электорат Коммунистической партии состоит из двух близких, но, тем не менее, отличающихся групп. Не исключено (это лишь гипотеза), что эти два близких гауссовых горба представляют из себя две группы электората — тех, кто жил при КПСС, и тех, кто ту эпоху уже не застал. Территориальную зависимость в голосовании за КПРФ можно попробовать проследить по фактору город/деревня, либо даже в пределах одного города по возрасту домов, которые относятся к данным УИК (в новостройках больше процент молодёжи, а в старых домах больше пожилых людей).
1.4) Задирание вверх графика распределения голосов на 100% для правящей партии и в 0% для остальных свидетельствует о фальсификации.
Не свидетельствует. Это естественный граничный эффект — в примере с Чингачгуком распределение размазано по вертикальным стенкам в 0% и 100% без всяких махинаций.
Как так получается, что у победившей партии нет пика в 0%, как у остальных, и наоборот, ни у кого, кроме победителя, нет пика на 100%? Любое распределение, которое левым краем упирается в 0%, будет иметь там острый пик, а любое распределение, достающее до 100% — там. Когда есть явный лидер в голосовании, никто кроме него до 100% не дотягивает, а сам победитель далёк от 0%.
1.5) На графике Б корреляция между явкой на избирательных участках и процентом голосов за правящую партию свидетельствует о вбросе бюллетеней с «нужными» голосами.
Для начала, очень важное соображение, которое упускают многие исследователи:
Наличие корреляции между величинами А и Б вовсе не означает наличия прямой причинно-следственной связи между ними.
Например, рассмотрим два параметра, характеризующих пожары в определённом городе:
А — нанесённый пожаром ущерб
Б — количество пожарных, участвовавших в ликвидации этого пожара
Между величинами А и Б существует высокая положительная корреляция — как правило, чем больший был нанесён ущерб, тем одновременно и больше пожарных участвовало в тушении. Но будет полным абсурдом утверждать, что ПРИЧИНОЙ большого ущерба стало большое количество пожарных. (См. статью «Корреляция» в Википедии.)
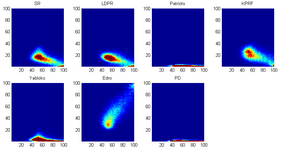
Результаты выборов в Парламент Великобритании 2010 показывают ещё более сильную зависимость между явкой и процентом голосов за разные партии:
| Корреляция с явкой голосов за ЕР и ЛДПР | Аналогичная картинка для выборов в Великобритании |
 | |
У этой зависимости может быть множество совершенно естественных причин. Почему конкретно так обстоят дела для Консервативной и Лейбористской партий в Великобритании я не знаю, но вот про корреляцию для российских реалий есть вполне чёткая логика.
В сознании законопослушных постсоветских граждан тесно связаны действия «прийти на выборы» и «проголосовать за действующую власть». Долгие годы однопартийной системы приучили людей к тому, что «сходить проголосовать» и «сходить проголосовать за власть» — синонимы. А правящая партия стойко ассоциируется с властью-вообще. Обычно за оппозиционную партию голосуют только те, кто твёрдо уверен в необходимости голосовать именно за неё. А за правящую партию голосуют в том числе и те, кто просто считает нужным «проголосовать», хотя и не особо-то разбирается в политике — просто так положено.
Вообще, игра на корреляции явки и процента голосов — вовсе не новость. Помните «Голосуй или проиграешь» в 1996-м? Штаб Ельцина выбрал очень грамотную линию — тащить на выборы молодёжь, которая одновременно а) за Ельцина (потому что против коммунистов) и б) крайне пассивна в плане «сходить на выборы». Аналогичную стратегию увеличения одновременно и голосов за себя, и общей явки использовал Билл Клинтон («Choose or lose»).
1.6) На графике Б наличие у правящей партии положительной корреляции, а у оппозиции — отрицательной свидетельствует о том, что часть голосов забрали у оппозиции и переписали их «куда надо».
Это совсем глупая ошибка, сильно дискредитирующая статьи Сергея Шпилькина и его последователей. Рассматривать явно ЗАВИСИМЫЕ величины и удивляться, что они взаимно коррелируют — вот уж действительно «чудо». Ведь число «явка» — это сумма количеств голосов за партии: A=K1+K2+...+Kn. Из (n+1) чисел {A,K1,K2,...,Kn} лишь (n) чисел могут быть независимы. Поэтому появления по какой-либо причине корреляции между голосованием за ОДНУ ЛЮБУЮ партию достаточно для появления корреляции и для всех остальных партий.
Допустим, на выборах в Америке-1760 появился третий кандидат — Оцеола, вождь семинолов, который призвал верных ему людей бойкотировать выборы. В результате на тех участках, где живут семинолы (и где естественный высокий процент голосов за Оцеолу) будет низкая явка — появится отрицательная корреляция: чем выше на участке явка, тем меньше там голосов за Оцеолу. Но, мало того, это автоматически приведёт и к появлению компенсирующей её положительной корреляции — чем выше на участве явка, тем больше там процент голосов за Чингачгука, хотя Чингачгук никоим образом к этому эффекту не причастен.
Ещё более грубая ошибка в расчётах корреляции заведомо зависимых величин (для случая, когда процент голосов высчитывается от списочного состава, как это делалось в оригинальных статьях Шпилькина) подробно разобрана здесь: http://xp-cmdshell.livejournal.com/273519.html
Категория 2. «Сумеречная зона — то ли есть, то ли нет, но что-то нехорошее точно мерещится.»
2.1) Вертикальные вырезы на графике А. Выше мы подробно обсудили, что реальное распределение вовсе не обязано быть гауссом из-за чисто географической неоднородности отношения к кандидату. Однако центральную предельную теорему всё-таки никто не отменял, и на участках, где всё более-менее однородно, должен быть гаусс (но только на отдельных участках!).
Таким образом, итоговый результат сложения всех этих участков будет суммой нескольких гауссовых «колоколов» — этакой многогорбой кривой. Однако, гауссы — ровные, и в середине распределения обычно довольно широкие. Поэтому получить путём их сложения отвесную вертикальную стенку естественным образом крайне сложно.
К сожалению, даже при таких объёмах данных, какие есть на всероссийских выборах, статистические выбросы слишком портят картинку, чтобы можно было с уверенностью утверждать наличие такой аномалии. На графике Единой России на выборах в ГосДуму 2011 есть подозрительные участки с почти вертикальными стенками на 36%, 65%, 70%, 79%, 90%. (Подробнее см. дальше, в Зоне тьмы.)
2.2) КОИБы и КЭГи
Наличие существенно различных картин данных с участков, где установлены комплексы обработки избирательных бюллетеней (КОИБ) и участков, где учёт бюллетеней ведётся вручную, ПРИ УСЛОВИИ, что КОИБы расставлены достаточно равномерно, также не может не вызывать подозрений. Однако ещё раз отметим — для того, чтобы данный фактор имел хоть какое-то значение, обязательно необходимо, чтобы статистика КОИБов была достаточно репрезентативной. Если КОИБы устанавливать только в салунах, не имея ни одного из них в вигвамах, то удивляться разнице в результатах голосования не приходится. А на данный момент расстановка КОИБов далека от равномерной (возможно, к президентским выборам ситуация изменится, да и веб-камеры обещают повесить).
Также при анализе корреляции следует учитывать «третий фактор» — из корреляции А и Б не следует то, что А является причиной Б, т.к. вполне возможно, что существует какой-то фактор В, из которого следуют оба — и А, и Б (помните аналогию про пожарников?). Например, низкий процент голосов за ЕР на автоматизированных участках в Коми может быть следствием вовсе не автоматизированности участков, а того, что, по словам самого исследователя, «на автоматизированные УИКи нагоняли людей с открепительными».
Наличие таких корреляций никогда не может быть строгим доказательством намеренной подтасовки, т.к. всегда остаётся шанс, что этот самый «третий фактор» существует, но просто не был найден.
Категория 3. «Зона кромешной тьмы.»
3.1) Многочисленные острые вогнутые пики на графике А. В п.2.1) мы пришли к тому, что хоть итоговый график распределения и не обязан быть гауссом сам по себе, он, скорее всего, должен состоять из нескольких (возможно, многих) гауссов. Эти рассуждения приводят нас к выводу о ненатуральности острых, направленных вверх пиков с вогнутыми вниз склонами (гауссы вблизи вершины выгнуты вверх!).
На данный момент автору не известны какие-либо разумные объяснения подобных аномалий, особенно когда они возникают на круглых значениях процентов, как это есть на уже упоминавшемся графике «ЕР: ГД 2011», его фрагмент приведён справа →
Это единственное достоверное статистическое подтверждение наличия фальсификаций на выборах в ГосДуму РФ 2011. Детальный анализ показывает, что за появление «шипованого хвоста» ответственны наши горячие и чересчур лояльные властям южные республики, что, в общем, совсем не удивительно.
3.2) Явные нарушения закона Бенфорда.
И, на десерт, исследование, которому уделяется незаслуженно мало внимания.
Дело в том, что «рукописные», сочинённые человеком числа с точки зрения самих ЦИФР, которыми записываются эти числа, отличаются от естественных. Причём эти закономерности противоречат нашему «бытовому» здравому смыслу, поэтому вручную их ОЧЕНЬ сложно сымитировать при фальсификации.
Цифр, как известно, 10. Из них первой цифрой числа может быть только 9 (все, кроме нуля). Поэтому, казалось бы, вероятность появления единицы среди первых цифр в колонке чисел должна быть 1/9=11%. Но на самом деле для огромного множества естественных наборов чисел вероятность того, что первой цифрой окажется единица, гораздо больше — 30%! Этот удивительный факт установил в 1938 году физик Фрэнк Бенфорд. И с тех пор он успел уже не только помочь в выявлении подлогов бухгалтерских отчётов, но и, что нас куда больше интересует, обосновал подозрения в фальсификации выборов в Иране (2009) (in english, по-русски).
В Википедии есть подробная статья про закон Бенфорда для случая первой цифры, но в полной форме он описывает встречаемость цифр на любой позиции. Чем ближе цифра к началу числа, тем ближе распределение вероятностей к бенфордовскому, а чем дальше — к равномерному.
Итак, вероятность появления данной цифры в качестве первой цифры числа логарифмически падает: единицу мы встретим в 30% случаев, а восьмёрку и девятку лишь в 5% (в шесть раз реже, чем единицу!).
Последние же цифры длинных чисел распределены равномерно — вероятность встретить в конце (длинного!) числа любую цифру обязана быть равна 10%.
Проверка закона Бенфорда для результатов выборов в ГосДуму 2011 (XLS).
По первой цифре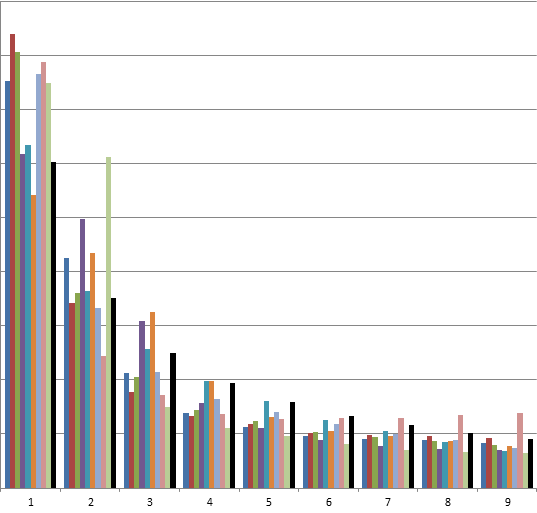 | По последней цифре (для чисел > 100)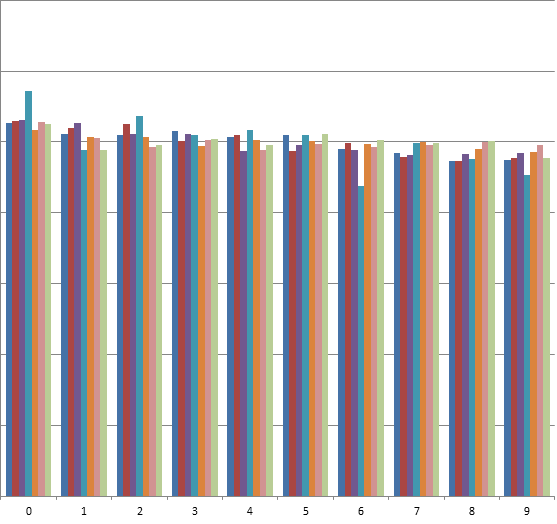 |
| Первые семь колонок — партии, затем: (розовая) — явка, (зелёная) — избирателей по списку, (чёрная) — сколько должно быть по Бенфорду Подробнее в экселе. |
Видно, что:
а) Закон Бенфорда для чисел голосов за партии (Единой России в том числе) выполняется просто фантастически красиво и для первой цифры, и для второй (см. xls), и для последней. Статистика выборов в ГосДуму 2011 — вообще уникальный массив данных для иллюстрации закона Бенфорда ;-)
б) Зелёная полоска на цифре «2» — объяснимый выброс. Списочное количество избирателей — не случайное число, на него действуют установленные ЦИК правила об оптимальном размере избирательного участка (видимо, порядка 1500-2500). Поэтому очень много участков, где 2*** избирателей, но резко меньше, где 3***.
Особенность закона Бенфорда в том, что он не работает, если есть хоть какая-то причина ему не работать (когда в системе существует заданный снаружи порядок вещей). Но когда таких причин нет — ему следует доверять.
в) На графике для первых цифр подозрительная «сумеречная» аномалия, касающаяся явки (розовая полоска). В хвосте распределения (цифры 5,6,7,8,9), где все партии логарифмически падают вместе с бенфордом, колонка явки не только не падает вместе со всеми, но и даже растёт!
| КПРФ | ЕР | явка | |
| 5 | 5,54% | 6,59% | 6,39% |
| 6 | 4,42% | 5,28% | 6,47% |
| 7 | 3,86% | 4,84% | 6,49% |
| 8 | 3,63% | 4,37% | 6,73% |
| 9 | 3,47% | 3,90% | 6,94% |
Категория 4. Фильсификации фальсификаций.
4.1. ruelect.com
Подивившись точности закона Бенфорда, я решил проверить его на ещё каком-нибудь наборе чисел. Под руку подвернулся сайт ruelect.com, на котором народ собирает «настоящие» протоколы голосований, дабы продемонстрировать, что они никак не стыкуются с данными ЦИК (ЕдРо, дескать, ворует голоса). Честно говоря, после таких новостей доверие к ruelect.com и без того пошатнулось, но результат всё равно меня поразил. Итак:
Степень соответствия закону Бенфорда количества голосов за ЕР: слева — по данным ЦИК, справа — по данным ruelect.com:
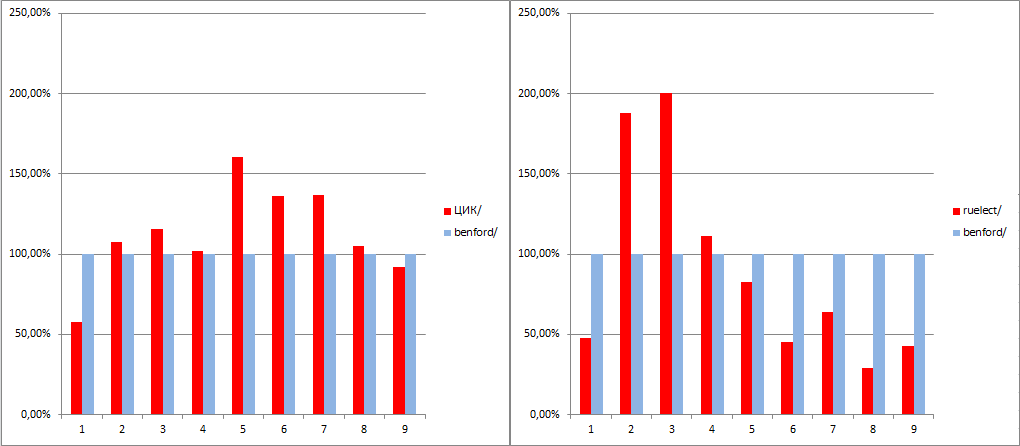
(На диаграмме показано отношение количества указанных первых цифр к прогнозируемому значению, следующему из закона Бенфорда.)
(В выборке, в т.ч. данных ЦИК, участвуют только те участки, которые приведены в базе ruelect.com.)
Видно, что якобы достоверные данные ruelect.com ГОРАЗДО ХУЖЕ следуют закону Бенфорда, чем якобы фальсифицированные данные ЦИК. Дабы не уподобляться «шаманам», поспешных выводов из этого факта я делать не буду, но подозрения он вызывает более чем серьёзные.
Соавторы и рецензенты:
Выпускник МФТИ, призёр всероссийской олимпиады по математике Сергей Тухвебер,
Выпускник МФТИ, ген. директор Eruditor group Егор Руди
Выпускник МФТИ, призёр всероссийской олимпиады по математике Сергей Тухвебер,
Выпускник МФТИ, ген. директор Eruditor group Егор Руди
Обсуждение (ЖЖ).
2012-03-01